【Python】Selenium:ブラウザ操作して静的・動的(Ajax、javascript)ページから情報を取得
公開日:更新日:

本記事ではPythonのSeleniumを利用した、ブラウザ上の静的・動的(Ajax、javascript)ページを操作して情報を取得する方法を解説します。
Pythonを使ってブラウザで行っている作業を自動化するアプリケーション(RPA)の作成や、データ収集の自動化をするアプリケーション(スクレイピング)を作成する場合、使用するモジュールとしてSeleniumが候補に上がります。
SeleniumはRequestsなどよりも高度なWebページ操作ができるので、RPAやスクレイピングといった様々なことが実現できます。
Seleniumについて学んで、今まで手作業で行っていたことを自動化できるようになりましょう!
本記事のプログラムは以下の環境で実行しております。
- OS:Windows10
- Google Chrome: 110.0.5481.178(Official Build)
- ChromeDriver:110.0.5481.77
- Python:Python 3.9.7
- Selenium:4.8.2
本記事を通して以下の知識を学べます。
- Seleniumモジュールについて
- Seleniumを使う前の準備について
- Seleniumの基本操作(ブラウザ操作、要素の検索・操作、HTML情報の取得)
Seleniumモジュール
Seleniumとは
Seleniumはブラウザを操作・制御するためのモジュールです。Seleniumモジュールを使用することでWebページのリンクやボタンをクリックしたり、ログイン情報の入力、Webページの情報取得などが可能となります。
Seleniumはスクレイピングによるデータ収集やブラウザの自動操作(RPA)でよく使用されます。最新のSeleniumを利用するためにはPythonはバージョン3.7以上が必要です。
スクレイピングとは、インターネット上の様々なWebサイトから自動的に数多くの情報を集める手法です
スクレイピングにはHTTP通信を行うRequests、HTML分析のためのBeautiful Soup 4が有名です。
SeleniumはRequestsよりも高度にWebページの操作ができます。しかしSeleniumはブラウザを操作するため、Requestsよりもスピードは遅く、バックグラウンドでの実行はできません。通常の静的なページからHTML情報を集めるだけであれば、Requestsを使用する方がいいです。
スクレイピングやRPA以外ではブラウザの動作検証でも使用されます。WEBサイトを構築した際に、正常に動作するかをテストする際にSeleniumを使用することもあります。
動的なページ(javascript、Ajax)でも使用可能
Webページの情報を取得する際に静的(static)なページであれば、HTTP通信を行うライブラリであるRequestsで事足ります。しかし動的なページ、つまりjavascriptやAjaxを使用しているページであればRequestsでは望む情報を取得できないことがほとんどです。
そこで動的なWebページから情報を取得する場合は、ブラウザの操作が可能なSeleniumを使用します。
Seleniumであれば、Ajaxやjavascriptをブラウザ上で動作させてから、望む情報を取得することができます。
BeautifulSoupと組み合わせる
スクレイピングではBeautifulSoupと組み合わせてSeleniumを使うと効果的です。
クローリングにはSeleniumを使い、スクレイピング(HTML分析)にはより高速なBeautifulSoupを使います。SeleniumではHTML分析が遅いので、より高速なBeautifulSoupを使うのが一般的です。
BeautifulSoup4の使い方については以下記事をご参照ください。

【Python】スクレイピング:BeautifulSoup4によるHTML解析
スクレイピングの注意事項
スクレイピングを行う場合、そのサイトの規約でスクレイピングが禁止されていないか確認することが必要です。特にログインする会員専用ページなどではスクレイピングが禁止されていることが多いです。
スクレイピングは相手のサーバーに大きな負荷をかけてしまうこともありますので、使用には十分注意してください。
Seleniumの準備
準備の流れ
Pythonが使える環境であることを想定して説明していきます。Seleniumを使用したプログラム作成をする前に、以下に記す事前準備を行ってください。
- Seleniumをインストール
- WebDriverをダウンロード
上記に記した事前準備の方法を見ていきましょう。
Seleniumをインストール
Seleniumは標準ライブラリではないため、pipコマンドでインストールする必要があります。
pip install seleniumPythonやライブラリのバージョンを管理できるように仮想環境を利用することをお勧めします。仮想環境の構築方法は以下記事をご参照ください。

【Python】仮想環境の構築と有効化の方法
WebDriverをダウンロード
Seleniumでブラウザを操作するにはそのブラウザに対応するWebDriverをダウンロードする必要があります。プリンターを使うときにそのプリンターのドライバをダウンロードするのと同じようなことです。
ブラウザはEdgeやIE、Chrome、Firefoxなど数多くありますが、本記事ではGoogle ChromeのWebDriverをダウンロードする方法を記載します。
EdgeのWebDriverのダウンロード方法や操作方法については以下記事をご参照ください。

【Python】Selenium:Edgeを自動操作する方法
まず下記リンクからGoogle ChromeのWebドライバーダウンロードページへ移動します。
ChromeDriver - WebDriver for Chrome
「All versions available in Downloads」の「Latest stable release」から最新のChromeDriverをダウンロードします。

次に使用しているOSのWebDriverを選択して、ダウンロードを開始します。私の場合はWindowsなのでWindows用ドライバをダウンロードします。
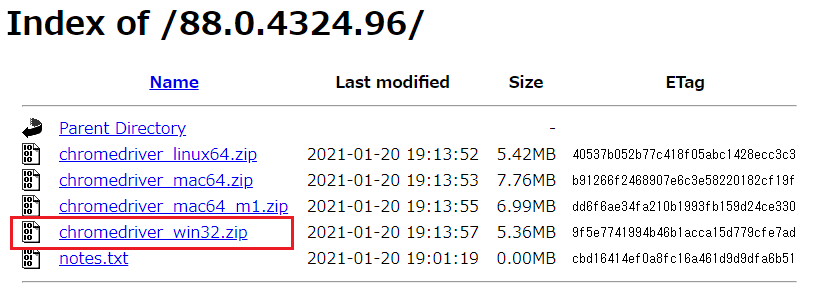
WebDriverはzipファイルでダウンロードされます。解凍して得られたexeファイルは使いやすい場所に保存してください。
2023年3月3日追記
現在では上記のサイトでは最新のドライバーをダウンロードできなくなっています。以下サイトから最新のドライバーをダウンロードするようにしてください。
静的・動的ページから情報(HTMLテキスト)を取得する流れ
静的・動的ページから情報(HTMLテキスト)を取得する流れを以下に記します。
- ブラウザの起動
- Webサイトへアクセス
- HTML要素を取得
- 取得した要素に対して操作(クリック、入力、ログイン処理)
- 動的ページの場合、Ajax・javascriptを動かす
- HTMLテキストを取得
上記の流れで対象のWebページからHTMLテキストを取得します。取得した後はBeautifulSoupを使用して、HTML分析(情報を抽出する)を行います。
seleniumの基本
seleniumのインポート
Seleniumを利用するために、まずはプログラムの先頭でseleniumのwebdriverをインポートします。
from selenium import webdriverSeleniumをインポートする際にimport seleniumとしないように注意してください
ブラウザ起動
webdriver.Chrome()を呼び出すとChromeのWebブラウザが起動します。
driver = webdriver.Chrome(executable_path=webdriver_path)
2023年3月5日追記
Seleniumバージョン4からはChrome()メソッドにexecutable_pathを利用するとDeprecationWarningが表示されます。

【Python】SeleniumでDeprecationWarning: executable_pathの対処方法
今後のアップデートではChrome()メソッドでのexecutable_pathは廃止されることが予想されるため、以下に記すサンプルコードのようにServiceオブジェクトを介してexecutable_pathを利用するようにしてください。
webdriver_pathには保存したWebdriverのパスを指定します。webdriver.Chromeの戻り値はWebDriverオブジェクトであることがtype()よりわかります。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
options = webdriver.ChromeOptions()
options.add_argument('--disable-gpu');
options.add_argument('--disable-extensions');
options.add_argument('--start-maximized');
options.add_experimental_option("excludeSwitches", ['enable-automation'])
chromedriver = 'C:\Office54\chromedriver.exe'
service = Service(executable_path=chromedriver)
driver = webdriver.Chrome(service=service, options=options)
print(type(driver))
# class 'selenium.webdriver.chrome.webdriver.WebDriver'
webdriver.Chromeより取得したWebDriverオブジェクトにはブラウザ操作や、Webページの要素を検索するためのメソッドが用意されています。
Webページへのアクセス
WebDriverオブジェクトに対してget()メソッドを使用することで引数に指定したURL先のWebページへアクセスします。
driver.get(url)
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
options = webdriver.ChromeOptions()
options.add_argument('--disable-gpu');
options.add_argument('--disable-extensions');
options.add_argument('--start-maximized');
options.add_experimental_option("excludeSwitches", ['enable-automation'])
chromedriver = 'C:\Office54\chromedriver.exe'
service = Service(executable_path=chromedriver)
driver = webdriver.Chrome(service=service, options=options)
driver.get("https://office54.net/")Webページ情報の取得
タイトルの取得
WebDriverオブジェクトに対してtitleを使用することでWebページのタイトルを戻り値で返します。
title = driver.titleURLの取得
WebDriverオブジェクトに対してcurrent_urlを使用することでWebページのURLを戻り値で返します。
url = driver.current_urlソースコード(HTMLテキスト)の取得
WebDriverオブジェクトに対してpage_sourceを使用することで、Webページのソースコード(HTMLテキスト)を戻り値で返します。
source_code = driver.page_sourceログイン操作やAjaxなどを動かして、対象ページまで移動できたら最後にpage_sourceを使用してHTMLテキストを取得します。
ブラウザ機能の使用
ブラウザページ操作(更新・戻る・進む)
WebDriverオブジェクトに対してrefresh()メソッド、back()メソッド、forward()メソッドを使用することで、Webページの更新・戻る・進む(取り消し)ができます。
driver.refresh() #更新
driver.back() #戻る
driver.forward() #進む(取り消し)
ページを閉じる
WebDriverオブジェクトに対してclose()メソッドを使用することで、開いているWebページを閉じることができます。
driver.close()ブラウザを閉じる
WebDriverオブジェクトに対してquit()メソッドを使用することで、WebDriverオブジェクト(ブラウザ)を閉じます。
driver.quit()ウィンドウの最大化
WebDriverオブジェクトに対してmaximize_window()メソッドを使用することで、ウィンドウを最大化できます。
driver.maximize_window()スクリーンショットの保存
WebDriverオブジェクトに対してsave_screenshot ()メソッドを使用することでブラウザのスクリーンショットを保存できます。
driver.save_screenshot(path)pathには保存先のパスを指定します。
HTML要素の検索
操作を行いたいWebページのHTML要素の検索方法について解説していきます。Webページのボタンクリックや、ログインのためにIDやパスワードの入力には、まず対象の要素を検索する必要があります。
WebページのHTMLを閲覧するには開発者ツール(デベロッパーツール)を使ってみてください。Windowsの場合はキーボードのF12キーで開発者ツールを開くことができます。
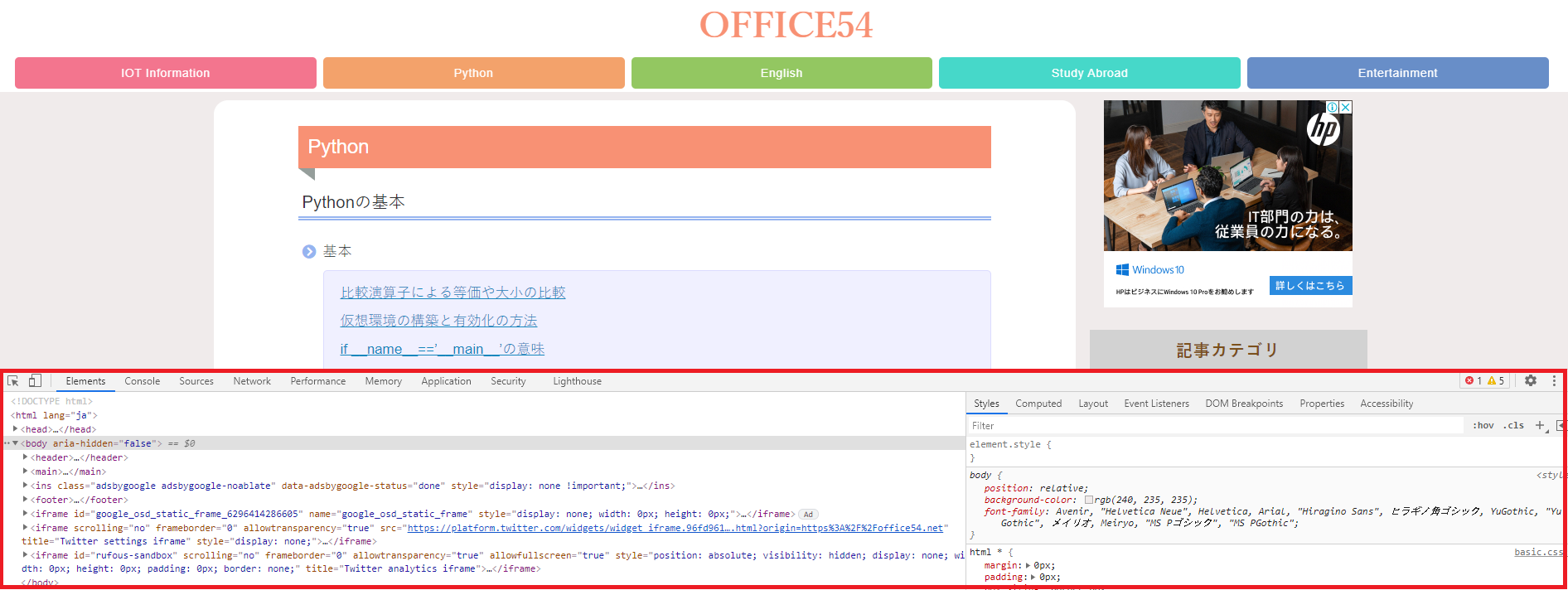
Seleniumバージョン4系
find_element()メソッドとfind_elements()メソッド
Seleniumのバージョン4系からはfind_element()メソッドとfind_elements()メソッドが使用できます。
最新バージョンのSeleniumを利用する方は後述するfind_element_by_*ではなくfind_element()メソッドを使いましょう。
Seleniumバージョン4.3.0以降はfind_element_by_*やfind_elements_by_*が廃止されました。もし4.3.0以降でこれらメソッドを使用するとAttributeErrorが発生するので注意が必要です

【Python】SeleniumでAttributeError: 'WebDriver' object has no attributeの対処方法
find_element()メソッドは条件にマッチした最初の要素を返し、find_elements()メソッドは条件にマッチした複数の要素をリストで返します。これらメソッドは以下構文に沿って使用します。
find_element(By class, element)
find_elements(By class, element)
第一引数のBy classには検索するための条件(id属性やclass属性、name属性など)を指定します。第二引数のelementで指定した文字列が、第一引数で指定した条件の要素と合致すると、その要素が返されます。
find_element()メソッドを使用する場合、必ずスクリプトの先頭でByクラスをインポートします。
from selenium.webdriver.common.by import By以下にfind_element()メソッドの使用例を記します。
<html>
<body>
<form id="form">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="login" type="submit" value="login" />
</form>
</body>
</html>
from selenium.webdriver.common.by import By
element_form = driver.find_element(By.ID, 'form')
element_username = driver.find_element(By.NAME, 'username')
上記コードではid属性がformの要素と、name属性がusernameの要素をそれぞれ見つけ、その要素を変数に格納しています。
find_element()の引数:By class
find_element()の引数By classに指定できる値は以下の通りです。
| By class | 説明 |
|---|---|
| By.ID | id属性 |
| By.CLASS_NAME | class属性 |
| By.NAME | name属性 |
| By.XPATH | Xpath |
| By.TAG_NAME | タグ名 |
| By.CSS_SELECTOR | CSSセレクタ |
| By.LINK_TEXT | リンクテキスト |
以下に各By Classを使用したコード例を記します。
<html>
<body>
<h1>OFFICE54</h1>
<p class= 'content'>content</p>
<form id="form">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="login" type="submit" value="login" />
</form>
<a href="top.html">Cancel</a>
</body>
</html>
from selenium.webdriver.common.by import By
element_form = driver.find_element(By.ID, 'form')
element_username = driver.find_element(By.NAME, 'username')
element_xpath = driver.find_element(By.XPATH, '/html/body/form[1]')
element_cancel = driver.find_element(By.LINK_TEXT, 'Cancel')
element_h1 = driver.find_element(By.TAG_NAME, 'h1')
element_content = driver.find_element(By.CLASS_NAME, 'content')
Seleniumバージョン4以前
find_element_by_*とfind_elements_by_*
古いバージョンのSeleniumではWebDriverオブジェクトに対してfind_element_by_*メソッドまたはfind_elements_by_*メソッドを使用することで、条件にマッチする要素を、WebElementオブジェクトを返します。
find_element_by_*メソッドは、条件にマッチした最初の要素をWebElementオブジェクトとして返します。
find_elements_by_*メソッドは、条件にマッチした複数の要素をWebElementオブジェクトのリストとして返します。
seleniumバージョン4.3.0以降はこれらメソッドを使用するとエラーが発生しますので、新しいバージョンのSeleniumでは利用しないようにしてください。
要素を検索するメソッド一覧
ページの要素検索の条件にはメソッドによってCSSセレクタ、id属性、class属性、name属性などを指定できます。
以下一覧表ではfind_element_by_*のメソッドを記しています。(elementをelementsにすれば複数要素のリスト取得になります)
ここでは変数driverに格納されたWebDriverオブジェクトに対してのメソッド実行方法を示しています。
| 指定要素 | メソッド |
|---|---|
| CSSセレクタ | driver.find_element_by_css_selector(CSS selector) |
| id属性 | driver.find_element_by_id(id) |
| class属性 | driver.find_element_by_class_name(class name) |
| name属性 | driver.find_element_by_name(name) |
| タグ名 | driver.find_element_by_tag_name(tag) |
| XPath | driver.find_element_by_xpath(XPath) |
各メソッドの引数は大文字・小文字を区別しますので注意してください。
またXPathによる要素の指定はとても便利な方法です。XPathが詳しくわからない方は以下記事をご参照ください。

XPathによる要素の指定方法:スクレイピング・RPAで利用しよう!
find_element_by_xpath()の使用方法については以下記事をご参照ください。

【Selenium】属性から要素を検索(指定):XPathの利用方法
HTML要素に対しての操作
HTML要素から検索して得られたWebElementオブジェクトには、クリックやテキスト入力、テキスト消去などができるメソッドが用意されています。
クリック
WebElementオブジェクトに対してclick()メソッドを使用することでその要素をクリックできます。
element.click()リンクのクリックや、ボタンのクリック、ラジオボタンの選択などマウスでクリックするのと同等の操作を行います。
ダブルクリックを要素に対して行うためにはAction Chainsという特殊な方法を用います。Seleniumでダブルクリックを行う方法については以下記事をご参照ください。

【Python】Selenium:ダブルクリックを実行する(Action Chains)
テキスト入力
inputやtextareaなどの要素に対してテキスト入力するにはsend_keys()メソッドを使用します。
element.send_keys(text)
send_keys()メソッドの引数textには、入力したいテキスト情報を指定します。フォーム入力やログイン操作でsend_keys()メソッドは使用されます。
テキスト消去
inputやtextareaなどの要素からテキストを消去するにはclear()メソッドを使用します。
element.clear()テキスト取得
inputやtextareaなどの要素から入力されているテキストを取得するにはtextを使用します。
element.text特殊キーの送信
SeleniumではEnterやCtrl、Shiptキーなどの特殊キーを送信することができます。
特殊キーを使いこなすことでJavaScriptやAjaxが使用されているWebサイトからも問題なくスクレイピングできますし、ブラウザ操作もできるようになります。
特殊キーの使い方については以下記事をご参照ください。

【Python】Selenium:Ajax非同期通信を特殊キー送信で実行させる
サンプルプログラム
以下に本サイトOFFICE54にアクセスして、Pythonタブをクリックするプログラムを記します。
from selenium import webdriver
driver = webdriver.Chrome(executable_path='chromedriver.exe')
url = "https://office54.net"
driver.get(url)
selector = 'header ul.category-name li.category-python a'
element = driver.find_element_by_css_selector(selector)
element.click()
まとめ
本記事「Selenium:ブラウザ操作して静的・動的(Ajax、javascript)ページから情報を取得」はいかがでしたか。
RPAの開発やスクレイピングプログラムの開発に利用されるSeleniumの基本的な使い方を解説してきました。
Seleniumにはここでは解説できていない、有用な機能がまだまだあります。今後もどんどん記事をアップしていきたいと思います。
この記事の執筆者


 関連記事
関連記事


















