【Python】PyPDF2でPDF内容を読み取りファイル名を変更するアプリ開発
公開日:更新日:

PythonのPyPDF2モジュールを使ったPDF内容を読み取ってファイル名を自動変更するアプリ開発について解説いたします。
このアプリを応用すれば仕事でも使えるアプリを作ることができると思います。
実際私が働いている外資系会社でもこのファイル名自動変更アプリを使用しています。
PyPDF2の使い方については下記リンクをご覧ください。

【Python】PyPDF2を使ってPDFからテキスト文字を読み取り・抽出する
それではPyPDF2を使ったデスクトップアプリ開発を学びましょう。
作成アプリ概要
これから解説するアプリの機能について簡単に解説します。
作成するアプリのGUI画面は以下になります。
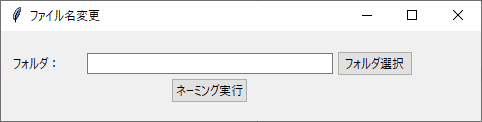
機能としてはフォルダを指定し、そのフォルダ内に格納されているPDFの名前をすべて変更します。
変更するファイル名はPDF1ページ目のテキスト(タイトル)を読み取り、それをファイル名とします。
基本的にこのままでは仕事で使えない人がほとんどだと思いますので、まずはどう作るのかをこの記事で学んでいただき、その後独自に使いやすいように作り直してください。
私の場合は、PDFから特定の文字列を読み取ったら、その内容をタイトルに追加するアプリを会社では使用しています。
注意事項として、PyPDF2モジュールは日本語には対応しておりませんので、日本語のPDFを読み取る場合は別のモジュールを使用する必要があります。
またPDFに関しても、紙の書類をただスキャンしたPDF(OCRしていないPDF)に関してもテキストを読み取ることができませんのでご注意ください。
tkinterによるGUI画面作成
import tkinter as tk
import tkinter.ttk as ttk
if __name__ == '__main__':
### GUI画面の作成 ###
# メインウィンドウの設定
root = tk.Tk()
root.title("ファイル名変更")
root.geometry("480x90")
# メインフレームの作成と設置
frame_setting = tk.Frame(root, relief="ridge")
frame_setting.pack(side="left")
# 各種ウィジェットの作成
label_folder = ttk.Label(frame_setting, text="フォルダ:", width=10)
entry_folder = ttk.Entry(frame_setting, justify="left", width=40)
button_folder = ttk.Button(frame_setting, text="フォルダ選択")
button_naming = ttk.Button(frame_setting, text="ネーミング実行")
# 各種ウィジェットの設置
label_folder.grid(row=0, column=0, padx=10, pady=2)
entry_folder.grid(row=0, column=1, sticky=tk.W + tk.E, padx=2, pady=2)
button_folder.grid(row=0, column=2, sticky=tk.W + tk.E, padx=2, pady=2)
button_naming.grid(row=1, column=1)
root.mainloop()tkinterを使ってGUI画面を作成します。
次に以下関数を上記プログラムに追加していきます。
button_folderをクリックしたらフォルダー選択画面を表示し、entry_folderにフォルダーパスを挿入する関数
button_namingをクリックしたら指定フォルダ内のPDFを読み取り、テキストを抽出・ファイル名を変更する関数
フォルダ指定関数の作成
以下にフォルダ指定関数のコードを記します。
from tkinter import filedialog as tkFileDialog
from pathlib import Path
import sys
# フォルダ選択を押下した場合の処理
def select_file_default_folder():
dir = Path(sys.argv[0]).parent.absolute()
fld = tkFileDialog.askdirectory(initialdir = dir)
entry_folder.delete(0, tk.END)
entry_folder.insert(0, fld)
select_file_default_folder関数内では、まず下記コードで実行ファイルが保存されているフォルダのパスをdirに格納します。
dir = Path(sys.argv[0]).parent.absolute()次にtkFileDialog.askdirectory()にdirを渡し、dirのパスから始まるディレクトリ選択画面を表示し、選択したフォルダパスをfldに格納します。
fld = tkFileDialog.askdirectory(initialdir = dir)entry_folderにfldを挿入する前に中身をすべてデリートし、その後fldをentry_folderに格納します。
entry_folder.delete(0, tk.END)
entry_folder.insert(0, fld)PDFのテキスト読み取り・抽出関数
以下にPDFのテキスト読み取り・抽出関数のコードを記します。
import PyPDF2
import glob
def file_naming():
files = glob.glob(os.path.join(entry_folder.get(), '*.pdf'))
for file in files:
with open(file, "rb") as f:
reader = PyPDF2.PdfFileReader(f)
page = reader.getPage(0) # 最初のページにアクセスする
text = page.extractText()
text = text.split('\n')
file_name = ''
for word in text:
file_name += word
file_name = file_name.strip()
file_name = os.path.dirname(file) + '/'+ file_name + '.pdf'
os.rename(file, file_name)
messagebox.showinfo("完了","ファイル名の変更を完了しました")
file_naming関数内では、まずglob.globメソッドにos.path.joinメソッドで取得したパス情報を渡して、フォルダ内に保存されているpdfファイル情報をfilesに格納します。
files = glob.glob(os.path.join(entry_folder.get(), '*.pdf'))for文でfiles内のファイル情報を一つ一つfileに格納してPDFからテキスト情報を取得しています。
for file in files:取得するのはPDFの1ページ目であり、取得したテキストはfile_nameに格納しています。
最終的にはos.renameメソッドでファイル名をfile_nameに格納したテキストに変換します。
with open(file, "rb") as f:
reader = PyPDF2.PdfFileReader(f)
page = reader.getPage(0) # 最初のページにアクセスする
text = page.extractText()
text = text.split('\n')
file_name = ''
for word in text:
file_name += word
file_name = file_name.strip()
file_name = os.path.dirname(file) + '/'+ file_name + '.pdf'
os.rename(file, file_name)
指定した文字列で抽出判定をする
私の場合、上記サンプルコードをそのまま使わずにPDFから採取したテキストをif判定して特定の文字列を取得し、それをファイル名としてリネームしています。
私のプログラムの想定としては、()内の文字列をファイル名にリネームするものです。
以下にそのソースコードを記します。
files = glob.glob(os.path.join(entry_default_folder.get(), '*.pdf'))
file_name = ''
for file in files:
with open(file, "rb") as f:
reader = PyPDF2.PdfFileReader(f)
page = reader.getPage(0) # 最初のページにアクセスする
text = page.extractText()
text = text.split('\n')
for word in text:
if word == "(":
start = word.find('(')
end = word.find(')')
file_name = word[start+1:end-1]
file_rename = os.path.dirname(file) + '/' + file_name + '.pdf'
os.rename(file, file_rename)
採取したテキスト群に"("があるかを一つ一つ確認しています。
ファイル名にしたいテキストが特定の文字列の後に位置する場合、この手法で目的のテキストを取得することができます。
まとめ
「【Python】PyPDF2でPDF内容を読み取りファイル名を変更するアプリ開発」はいかがでしたでしょうか?
PyPDF2にはその他にも使える機能があるので、そちらも使ってみてください。
この記事の執筆者


 関連記事
関連記事
















