XPathによる要素の指定方法:スクレイピング・RPAで利用しよう!
公開日:更新日:

本記事ではPythonなどで開発されるスクレイピングやRPAのアプリケーションで利用される、XPathについて詳しく解説していきます。
スクレイピングやRPAで要素を指定する際、XPathは重要な役割を果たします。XPathを理解することで、要素の指定がぐっと楽になります。
本記事を通して以下のことを学べます。
- XPathの概要と基本構成
- ロケーションパスの作成方法
- XPathを利用した属性・テキストによる要素の指定
- XPathで使用できる関数群
XPath
XPathとは
XPath(エックスパス)とはXML Path Languageの省略形で、XMLやHTML文書から要素や属性を指定するクエリ言語です。
XMLやHTMLは階層構造(ツリー構造)となっており、その特性を利用して対象の要素を指定します。
WebサイトはHTMLで記述されているため、HTMLを解析して動くようなプログラムではXPathが利用されます。
例として以下のHTML文章を見てみましょう。
<html>
<body>
<h1>OFFICE54</h1>
<div class="main">
<ul>
<li class="title">IT Information</li>
<li class="title">Python</li>
<li class="title">Django</li>
</ul>
</div>
</body>
</html>
これを階層構造の図で表すと以下のようになります。
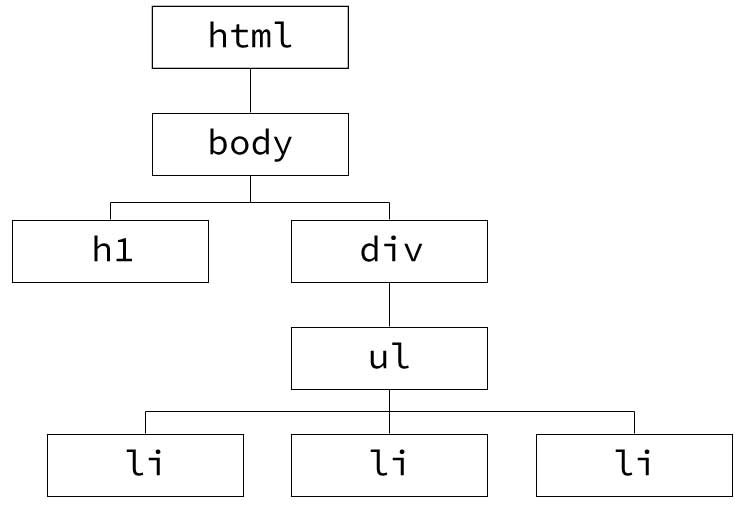
このHTML文章内のh1要素をXPathで指定すると次のようになります。
/html/body/h1
<h1>OFFICE54</h1>
XPathでは要素(ノード)を上記のようなパス表記で表します。このような各ノードを「/(スラッシュ)」で区切りながら階層を記述したものをロケーションパスと呼びます。
ロケーションパスの記述方法は後ほどくわしく解説します。
- XPathはXML/HTML文書から要素や属性を指定する言語
- 要素までの道筋を記述したものをロケーションパスと呼ぶ
使用する場面
XPathはPythonやJava、C#といったプログラミング言語でXML/HTML文書を扱う際に使用されます。
特にスクレイピングやRPAではWebページのHTMLを利用して動くため、XPathによるHTMLの指定をすることが多いです。
PythonはスクレイピングやRPAの分野で最も人気のある言語です。XPathはPythonのScrapyやSeleniumといった多くのライブラリに対応しています。
スクレイピングで利用されるPythonのBeautifulSoupはXPathをサポートしていません
WebサイトからXPathの取得:開発者ツール
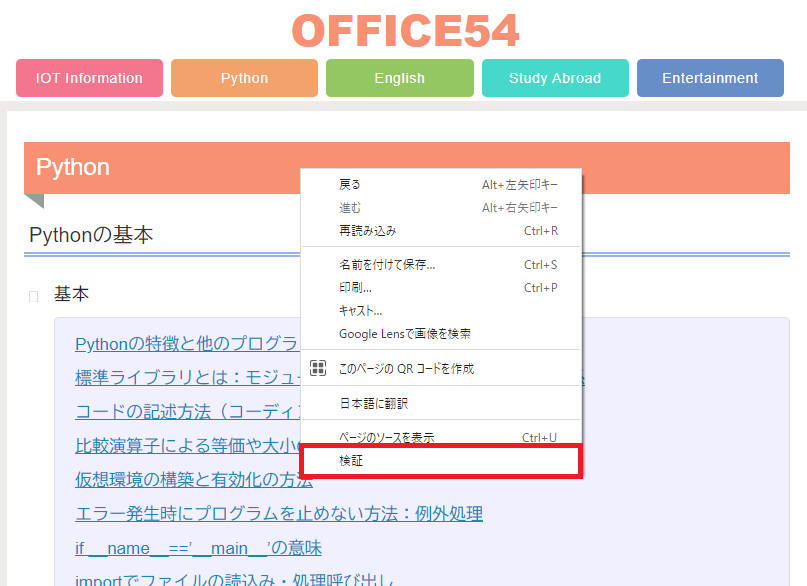
Webサイト上からXPathを取得したい場合、開発者ツールを利用すると簡単にXPathをページの要素から取得できます。
Google Chromeでの開発者ツールを使ったXPathの取得方法を以下に記します。
- 対象のサイトで右クリック>検証を選択
- 要素を選択し右クリック>Copy>Copy XPathを選択
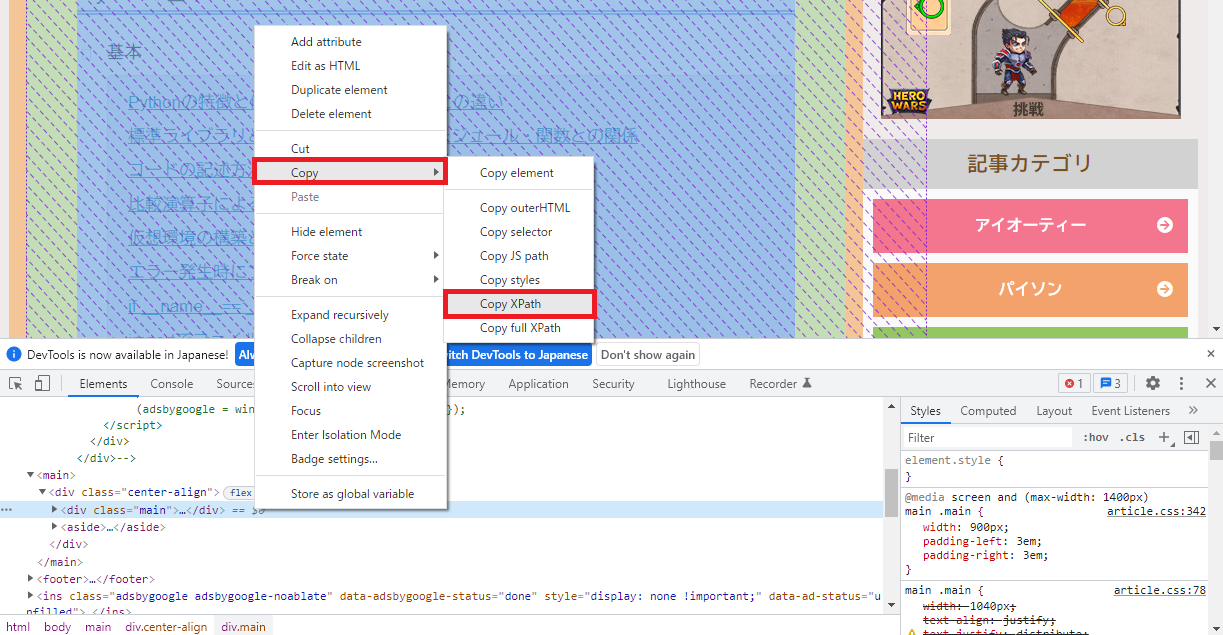
上記の方法で選択したXPathをコピーできます。
スクレイピング・RPAを作成する場合
私がPythonでスクレイピングまたはRPAのアプリケーションを作成する場合、開発者ツールをよく利用します。
ここで解説したXPathの取得方法ではXPathを取得するだけでなく、その要素のセレクターも取得できます。
XPathまたはセレクターで要素を特定し、要素のクリックや値の取得などを行っています。
XPathの練習サイト
XPathはただやり方を眺めているだけではわかりづらいものです。そこで実際に手を動かして、XPathを覚えていきましょう。
以下のサイトではXPath(ロケーションパス)を実際に記入しながらその結果を確認することができます。
ぜひこのサイトを利用しながら次項以降で解説するXPathの記述を覚えてください。
ロケーションパス
ここでは以下HTML文書を元にロケーションパスの記述方法を解説していきます。
<html>
<body>
<h1>OFFICE54</h1>
<div class="main">
<ul>
<li class="title">IT Information</li>
<li class="title">Python</li>
<li class="title">Django</li>
</ul>
</div>
</body>
</html>
基本的な記述方法
すでに説明していますが、ロケーションパスはHTMLの階層構造を利用し、各ノードを「/(スラッシュ)」で区切り、要素までの道のりを示します。

ルートノードから対象の要素までを記述したロケーションパスを絶対XPathとも呼ばれます。
テキストの取得:text()
HTMLの要素は以下のような構成になっています。

この要素からテキストを取得するにはtext()を使用します。
/ノード/…/text()
例えばh1からテキスト「OFFICE54」を取得するには以下のように記述します。
/html/body/h1/text()
# OFFICE54
ロケーションパスの省略://(ダブルスラッシュ)
毎回わざわざルートノードからロケーションパスを記述するのは面倒くさいです。
そこで//(ダブルスラッシュ)を使うことでパスを省略(短縮)して記述することができます。
例えばHTML文章中のh1を指定したい場合は以下のように記述できます。
//h1
とても短くなりましたね。この結果は/html/body/h1と同等です。
しかし//(ダブルスラッシュ)には注意点があります。HTML中に同じ要素が存在した場合、複数の結果がかえされます。
上記例では、HTML文章中にh1要素が複数あった場合、複数の結果が返ってきてしまうということです。
スクレイピングやRPAでは要素を1つに絞り込んで指定する必要があります。
そこで要素を1つに絞り込めるようにロケーションパスに親要素を含めるか、idなどの属性を指定するようにしましょう。
XPath:属性による要素の指定
XPathでは属性で要素を指定することができます。属性で要素を指定できると、要素の特定がとても簡単になります。詳しく見ていきましょう。
ここでは以下コードを利用して要素の指定を解説していきます。
<html>
<body>
<h1>OFFICE54</h1>
<div class="main">
<ul>
<li class="title" id="it">IT Information</li>
<li class="title" id="python">Python</li>
<li class="title" id="django">Django</li>
</ul>
</div>
</body>
</html>
属性とは
属性とはHTMLの要素に性質を与える仕組みです。
要素の開始タグに「属性名=属性値」の書式で記述します。属性は複数指定することが可能であり、半角スペースで区切って指定できます。
<要素名 属性名1=属性値 属性名2=属性値>…</要素名>
主に利用される属性は以下のようなものがあります。
| 属性名 | 説明 |
|---|---|
| id | 要素に固有の名前を指定 |
| class | 要素に分類名を指定 |
| title | 要素に補足情報を指定 |
| style | 要素にCSSの効果を適用 |
属性の指定
XPathでは属性名を「@」で表します。例えば属性名idは「@id」とします。
属性を持つ要素を表すにはXPathでは以下の構文で記入します。
//タグ名[@属性名=属性値]
例えばliタグのPythonを指定するには以下のようにします。
//li[@id="python"]すべての要素で特定の属性を持つ要素を抽出したい場合は以下の構文で記入します。
//*[@属性名=属性値]
上記のようにタグ名をアスタリスクにすることですべての要素を検索範囲とします。
例えばclassがtitleの要素を抽出する場合は以下のようにします。
//*[@class="title"]
# <li class="title" id="it">IT Information</li>
# <li class="title" id="python">Python</li>
# <li class="title" id="django">Django</li>
XPath:テキストによる要素の指定
開始タグと終了タグに挟まれているテキストで要素を指定するにはtext()関数を使用します。
//タグ名[text()="テキスト"]
例えばliタグのテキストがPythonである要素を指定する場合は以下のようにします。
//li[text()="Python"]
# <li class="title" id="python">Python</li>
XPath:使用できる関数・メソッド
contains()
属性値のあいまい検索(部分一致)
要素の属性値からあいまい検索(含まれる文字列で検索)したい場合はcontains()を使用します。
contains(@属性名, "属性値に含まれる文字列")
例えばliタグからclassにtitが含まれる要素を指定する場合は以下のようにします。
//li[contains(@class, "tit")]
# <li class="title" id="it">IT Information</li>
# <li class="title" id="python">Python</li>
# <li class="title" id="django">Django</li>
テキストのあいまい検索(部分一致)
要素のテキストからあいまい検索(含まれる文字列で検索)したい場合はcontains()とtext()を使用します。
contains(text(), "テキストに含まれる文字列")
例えばliタグからテキストにPytを含む要素を指定する場合は以下のように記述します。
//li[contains(text(), "Pyt")]
# <li class="title" id="python">Python</li>
position():要素を順番で指定
liタグやthタグなど同じタグが複数続く場合に順番で要素を指定するにはposition()を使用します。
例えばliタグで3番目の要素を指定したい場合は以下のように記述します。
//ul/li[position()=3]
# <li class="title" id="django">Django</li>
上記の指定方法は以下と同義になります。
//ul/li[3]またliタグで1番目以上の要素を指定する場合は以下のように記述します。
//ul/li[position()>1]
# <li class="title" id="python">Python</li>
# <li class="title" id="django">Django</li>
starts-with:属性値を前方一致検索
ある属性の属性値を前方一致で検索するにはstarts-with()を使用します。
starts-with(@属性名, "前方一致で検索したい属性値")
例えばidで属性値がpyから始める要素を指定する場合は以下のように記述します。
//li[starts-with(@id, "py")]
# <li class="title" id="python">Python</li>
ends-with:属性値を後方一致検索
ある属性の属性値を後方一致で検索するにはends-with()を使用します。
例えばidで属性値がgoで終わる要素を指定する場合は以下のように記述します。
//li[ends-with(@id, "go")]
# <li class="title" id="django">Django</li>
XPath:複数条件で要素を指定
and
XPathで複数の条件に一致する要素を指定するにはandを利用します。
例えばliタグでclassがtitle、idがpythonの要素を指定するには以下のように記入します。
//li[@class="title" and @id="python"]
# <li class="title" id="python">Python</li>
or
XPathでいずれかの条件に一致する要素を指定するにはorを利用します。
例えばliタグでidがitまたはdjangoの要素を指定するには以下のように記入します。
//li[@id="django" or @id="it"]
# <li class="title" id="it">IT Information</li>
# <li class="title" id="django">Django</li>
not
XPathで条件に一致しない要素を指定するにはnotを利用します。
例えばidがdangoまたはitではないliタグの要素を指定するには以下のように記入します。
//li[not(@id="django" or @id="it")]
# <li class="title" id="python">Python</li>
まとめ
本記事「XPathによる要素の指定方法:スクレイピング・RPAで利用しよう!」はいかがでしたか。
私はよくスクレイピングやRPAのアプリケーションを作成していますが、XPathはとても役立っています。複雑なWebアプリケーションの場合、XPathでないと指定しづらい要素が非常に多くなるからです。
ぜひXPathを使っていただき、この便利さを体感してください。
この記事の執筆者


 関連記事
関連記事










