【機械学習】学習データの収集について:データセット、スクレイピング
公開日:更新日:

本記事では機械学習における、学習データの収集方法について解説していきます。
機械学習では事前に大量の学習データを集めておく必要があります。この学習データによって、機械学習モデルの精度は大きく変わります。
学習データの収集には、一般に公開されているデータセットの利用や、スクレイピングによる目的のデータを収集する方法などがあります。
本記事を通して、機械学習で利用する学習データの収集方法に関する理解を深めましょう。
機械学習とは
機械学習は人間の学習能力をコンピューターで実現する技術であり、現代では最も注目されている分野の一つと言っても過言ではありません。
本屋に足を運ぶと、様々な機械学習(AIやディープラーニングを含む)書籍がたくさん置いてありますよね。ビジネスでも多方面で機械学習を利用したアプリケーションの開発や利用が行われています。
機械学習を利用したシステムを作成する流れは次のようになります。
- データの収集
- データの整形(前処理)
- データを学習(機械学習)
- 学習済みモデルが生成される
- 学習済みモデルを評価(精度評価)
- 学習済みモデルをシステムに組み込む
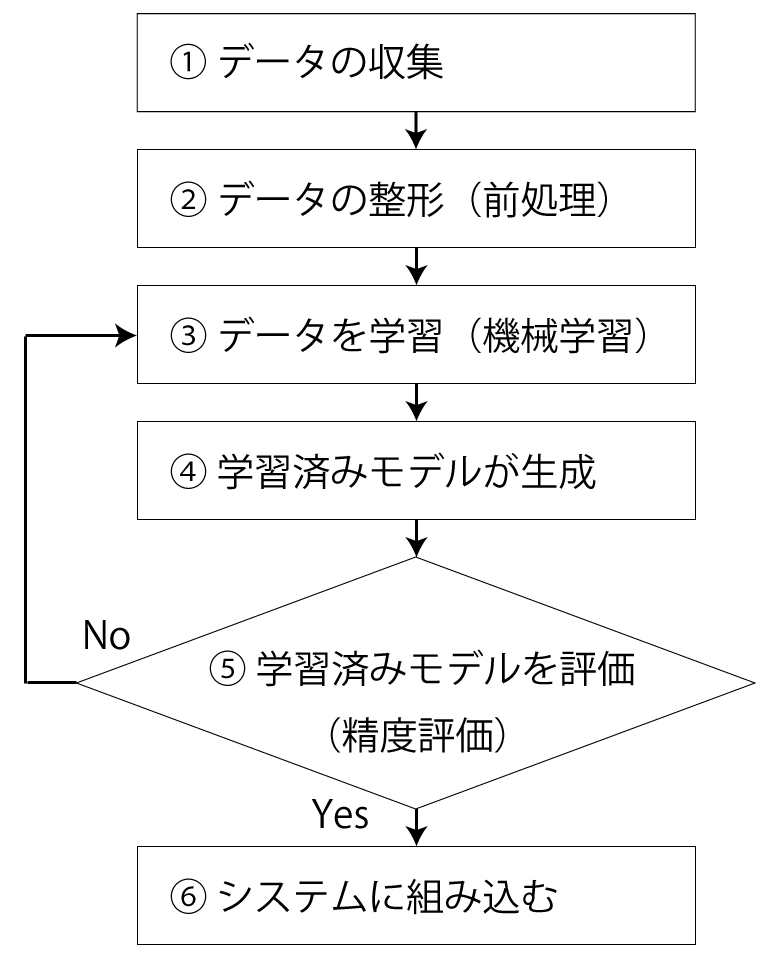
本記事では上記流れの一番初めに行う「データの収集」について詳しく解説していきます。
機械学習について詳しくは以下記事をご参照ください。

機械学習とは?特徴や使用用途(ビジネス)、利用例について
機械学習:学習データの収集
機械学習を用いたシステムを構築するには、まず初めに大量のデータを収集する必要があります。大量のデータがない場合、効果的な学習を行うことができません。
一昔前まではデータ収集が困難でしたが、現在ではインターネットが普及したため大量のデータが集めやすくなりました。
大量に集めたデータを使って学習を行い、学習済みモデル(学習から作成されたルールや法則)を生成していきます。
必要な学習データの量は、作成するシステムや目的などによって異なります。
学習データの収集方法
大量の学習データを集める方法は大きく分けて以下の3種類があります。
- 公開データ(データセット、オープンデータ)の利用
- インターネット上(Web)から収集(APIやスクレイピングなどを利用)
- 自前の蓄積したデータの利用
公開データ(データセット、オープンデータ)の利用
機械学習で利用できる様々なデータセットはだれでも利用できる形で一般に公開されています。またこれらデータセットで学習した学習済みモデルも公開されています。
機械学習のコンペティションプラットフォームであるKaggle(カグル)には様々なデータセットが提供されています。どんなデータセットがあるのか一度覗いてみてください。
Kaggle(カグル)とは
Kaggle(カグル)とは世界最大級の機械学習コンペティションプラットフォームです。2010年にサービスが開始され、今ではGoogleに買収され、Google傘下の企業となっています。
企業や政府、大学がコンペティション形式で課題を提示し、世界中のデータサイエンティストたちが競い合います。上位成績者には賞金やメダルが与えられます。
機械学習の上級者だけでなく、初心者でもKaggleは利用すべきサービスです。初心者でも勉強できるように「Kernels」という機能があり、モデルやコードが理解しやすいようになっています。
Kaggleのほかにも、日本政府が公開しているオープンデータと呼ばれるデータセットのまとめサイトもあります。

顔認証の画像データはMegaFaceからデータセットを取得できます。ワシントン大学の顔認証アルゴリズムの競技で利用されています。
このようなすでに用意されているデータセットを利用することで、大量のデータを集める労力を少なくすることができます。
インターネット上(Web)から収集
インターネット上には大量のデータが存在します。これら大量のデータから機械学習で必要になるデータを収集することができます。
インターネット上からデータを収集する方法としては次のような方法があります。
- 公開されているWeb APIから情報の取得
- スクレイピングによるWebページから情報の取得
Webページからデータを集める手法をスクレイピングと呼びます。スクレイピングはPythonが得意とする分野であり、RequestsやBeautiful Soup 4、Seleniumといったライブラリを利用します。これからスクレイピングを学習する方は以下記事を参考にしてみてください。

【Python】Selenium:ブラウザ操作して静的・動的(Ajax、javascript)ページから情報を取得

【Python】スクレイピング:BeautifulSoup4によるHTML解析
自前の蓄積したデータの利用
自前で用意したデータを利用することもできます。自社の専用アプリケーションを作成する際では、過去数年で蓄積したデータを利用することもあります。
例えばレストランでは、過去の売り上げ、客単価、その日の天気など様々なデータを利用して、売上予測プログラムを作成することができます。
まとめ
本記事「【機械学習】学習データの収集について:データセット、スクレイピング」はいかがでしたか。
学習データの収集を効率的に行って、精度の高い機械学習モデルを作成できるようになりましょう。
この記事の執筆者


 関連記事
関連記事










