【機械学習】scikit-learn(sklearn)とは?特徴や使用方法について
公開日:更新日:

本記事ではPythonの機械学習における、有名な機械学習フレームワークの一つ「scikit-learn」について詳しく解説していきます。
scikit-learnは機械学習で使われる様々なアルゴリズム(教師あり学習(分類、回帰)や教師なし学習(クラスタリング、次元削減))やデータの前処理などをサポートしています。
また機械学習初心者でも扱えるようにサンプルデータも用意されているため、これから機械学習を学び始める人にうってつけのライブラリとなっています。
本記事を通して、scikit-learnの特徴や使用方法について理解を深めてください。
機械学習について詳しく知りたい方は以下記事をご参照ください。

機械学習とは?特徴や使用用途(ビジネス)、利用例について
scikit-learnとは
scikit-learn(サイキット・ラーン)はPythonで利用できる機械学習用のライブラリです。機械学習を初めて学ぶという方に適したライブラリで、個人・商用問わず無料で利用することができます。

機械学習を扱っている書籍では、まず初めにscikit-learnから学ぶことが多いです。
scikit-learnは2007年にGoogle Summer of Code projectで開発がすすめられ、現在でも開発は継続しています。
機械学習を勉強し始める多くの人がscikit-learnから使い始めるのは、 豊富に機械学習のアルゴリズムが用意されていることや、豊富なサンプルデータが搭載されていることが主な理由です。
アルゴリズムの選択においてもチートシートが用意されており、目的に基づいて適切なアルゴリズムを選択できます。
scikit-learnの特徴
scikit-learnの特徴を以下に記します。
- 機械学習で利用するアルゴリズムを豊富に揃えている
- オープンソースであり無料で使用できる
- サンプルのデータセット(トイデータセット)が豊富
- アルゴリズムの選択で利用するチートシート
それぞれの特徴について見ていきましょう。
機械学習で利用するアルゴリズムを豊富に揃えている
scikit-learnは教師あり学習(分類、回帰)や教師なし学習(クラスタリング、次元削減)の手法やモデルの選択と評価、学習データの前処理ができます。
- 教師あり学習(分類、回帰)の手法
- 教師なし学習(クラスタリング、次元削減)の手法
- モデルの選択と評価
- 学習データの前処理
教師あり学習や教師なし学習について詳しくは以下記事をご参照ください。

【機械学習】学習の手法:教師あり学習・教師なし学習・強化学習の特徴や違い
教師あり学習
教師あり学習とは、学習データと答えとなる正解(ラベル)を与えて学習を行う手法です。
教師あり学習の利用には回帰と分類の2種類があり、scikit-learnではどちらもサポートしています。
アルゴリズムには決定木やランダムフォレスト、線形モデル、ロジスティック回帰、SVM、最近傍探索などが用意されています。
教師なし学習
教師なし学習とは、学習データに正解(ラベル)がなく、データのみが与えられる手法です。
教師なし学習の利用にはクラスタリングと次元削減があり、scikit-learnではどちらもサポートしています。
モデルの選択と評価
scikit-learnには生成したモデルを評価して選択するための機能も備えています。各種評価指標の算出やハイパーパラメータのチューニングといった機能があります。
これらを利用して、機械学習でうまく学習ができたかを確認・評価することができます。
学習データの前処理
機械学習では学習をはじめる前に大量のデータを収集しておく必要があります。そして収集した学習データはそのまま利用できません。
収集した学習データは前処理と呼ばれる、学習データを機械学習で扱えるデータ形式に変換する処理を行います。
機械学習では非常に重要とされる「データの前処理」をscikit-learnで行うことができます。
オープンソースであり無料で使用できる
scikit-learnはオープンソースであるため無料で個人・商用で利用することができます。
ライセンス体系はオープンソースソフトウェアで使われるBSDライセンス(Berkeley Software Distribution License)です。
サンプルのデータセット(トイデータセット)が豊富
本来機械学習では大量の学習データを用意し、前処理をする必要があり、これに膨大な時間を取られてしまいます。
しかしscikit-learnには豊富なサンプルデータセットが用意されているため、すぐに機械学習を体験することができます。
アヤメの種類、手書き文字、糖尿病患者などのサンプルデータが用意されており、いろいろなアルゴリズムを実際に触って試すことができるようになっています。
用意されているサンプルデータセット以外のデータも利用してみたい方はインターネット上に公開されているデータセットも使ってみてください。インターネット上で公開されているデータセットについて詳しくは以下記事をご参照ください。

【機械学習】学習データの収集について:データセット、スクレイピング
アルゴリズムの選択で利用するチートシート
scikit-learnには様々なアルゴリズムが用意されています。そのためどの手法を利用すればいいのか、初心者には選択するのが難しいところです。
そういった悩みを解決するためのチートシートが公式サイトに用意されています。
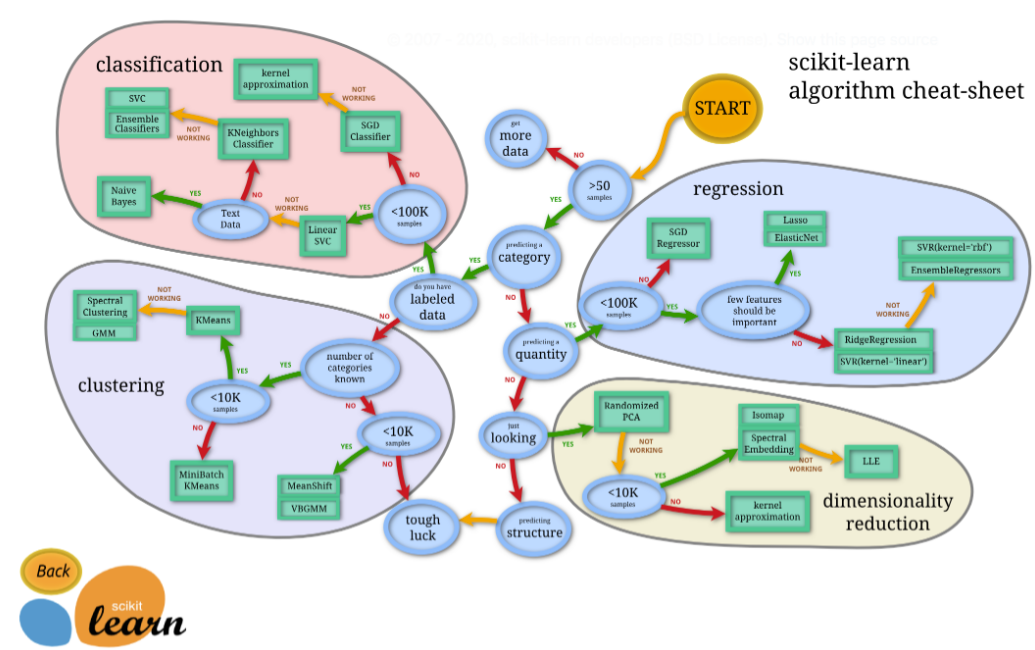
このチートシートを利用することで目的に応じた最適なアルゴリズムを選択できるようになります。Startから初めて2択の選択を進めていくだけなので非常に簡単です。
まだアルゴリズムに精通していない初心者でもすぐに機械学習が試せるようになっているのは嬉しいことですね。
scikit-learnのインストール
scikit-learnは標準ライブラリではないため、pipコマンドでインストールする必要があります。
pip install scikit-learnAnacondaを利用している場合は、最初からscikit-learnはインストールされていますので、上記コマンドでインストールする必要はありません。
scikit-learnによるSVMの利用
ここではscikit-learnでSVM(Support Vector Machine)を使用する基本的な方法について解説していきます。
SVMとは
SVM(Support Vector Machine)は教師あり学習の分類と回帰どちらにも利用できる機械学習のアルゴリズムです。主に「分類」に利用されることが多いです。
SVMは分類ではSVC(Support Vector Classification)、回帰ではSVR(Support Vector Regression)と呼ばれることもあります。
SVMには以下の特徴があります。
- 少ない学習データ量で高い性能を持てる
- 高速で信頼性が高い
- 過学習を起こしづらい
SVMのインポート
Pythonのスクリプトでscikit-learnを利用する場合、スクリプトの先頭でsvmをインポートする必要があります。
from sklearn from svmSVMオブジェクトの生成
SVMのアルゴリズムを利用するためのSVMオブジェクトをsklearn.svm.SVC()で生成することができます。
from skleran import svm
clf = svm.SVC()
上記コードでは生成したSVMオブジェクトを変数clfに格納しています。
fit()メソッド:データの学習
fit()メソッドは与えられたデータを学習するために使用します。sklearn.svm.SVC()で生成したSVMオブジェクトに対して使用します。
fit(training data, label, sample_weight=None)
fit()の第一引数には学習データの配列、第二引数にはラベル(答えのデータ)を指定します。
from skleran import svm
clf = svm.SVC()
clf.fit(data, label)
上記コードでは学習データをdata、ラベルをlabelに格納して、それぞれfit()の引数に指定しています。
predict()メソッド:データの予測
predict()メソッドは学習した結果からデータを予測します。fit()メソッドで十分に学習していれば、predict()による予測は正確性が高くなります。
predict(data)
predict()の引数には予測したいデータの配列を指定します。返り値は指定したデータの数だけ予測結果を返します。
from skleran import svm
clf = svm.SVC()
clf.fit(data, label)
pre = clf.predict(data)
print(pre)
accuracy_score()メソッド:正解率を求める
sklearn.metrics.accuracy_score()を利用すると機械学習による正解率を求めることができます。
sklearn.metrics.accuracy_score(correct labels, predicted labels)
accuracy_score()の第一引数には実際の答え、第二引数には予測結果を指定します。返り値は正解率を返します。
import metrics
score = metrics.accuracy_score(label, pre)
scikit-learnのSVM:サンプルコード
ここでは排他的論理和をSVMで学習させて、データを予測させるサンプルコードを記します。
たった4つのデータしか学習させないため、現実的なプログラムではないです。ただどのように学習と予測を行うか参考にしてください。
from sklearn import svm, metrics
xor_data = [
[0 ,0, 0],
[0, 1, 1],
[1, 0, 1],
[1, 1, 1]
]
data = []
label = []
for row in xor_data:
p = row[0]
q = row[1]
r = row[2]
data.append([p, q])
label.append(r)
clf = svm.SVC()
clf.fit(data, label)
pre = clf.predict(data)
print('予測:', pre)
score = metrics.accuracy_score(label, pre)
print('正解率:', score)
# 予測: [0 1 1 1]
# 正解率: 1.0
上記サンプルコードでは、配列dataに学習データを格納し、配列labelにラベル(答え)を格納してfit()メソッドで学習させています。その後predict()メソッドで予想させ、accuracy_scoreで正解率を求めています。
上記のようにscikit-learnのSVMで学習と予測を行います。
まとめ
本記事「【機械学習】scikit-learn(sklearn)とは?特徴や使用方法について」はいかがでしたか。
scikit-learnから初めて、機械学習についてどんどん理解を深めていってください。
この記事の執筆者


 関連記事
関連記事








