【機械学習】特徴量とは?意味や変数、選択について
公開日:更新日:

本記事では機械学習における、特徴量について詳しく解説していきます。
機械学習において重要な概念の1つが特徴量です。特徴量を理解せずに機械学習で製品を作ることは不可能です。
特徴量の役割や変数、特徴量選択についても本記事を通して理解を深めてください。
機械学習とは
機械学習とは人間の脳(学習能力)をコンピューターで実現する技術です。学習と名がつくように、コンピューターに用意した大量のデータを学習させます。
データを大量に学習させることで、それらデータのパターンや法則を見つけ出し、将来を予測することや未知のデータの分類などに利用します。
ディープラーニングから機械学習を知ったという方も多いと思います。ディープラーニングは機械学習を高度に発展させたもので、機械学習の一種と言えます。
機械学習について詳しくは以下記事をご参照ください。

機械学習とは?特徴や使用用途(ビジネス)、利用例について
特徴量(feature)
特徴量とは
特徴量(feature)とはモデルが予測を行うために使うことができるデータの特性または属性のことです。よりわかりやすく言うと、
特徴量はデータの中から予測・分類するための手掛かりとなる変数です。
機械学習は大量のデータを学習し、未知のデータを分類または将来を予測することを目的としています。この目的を果たすためにデータの特徴(特徴量)に着目し、目的を達成できる学習済みモデルを構築します。
イメージしやすいのが、データがテーブル(表形式)に含まれている場合は、テーブルの列が特徴量となります。
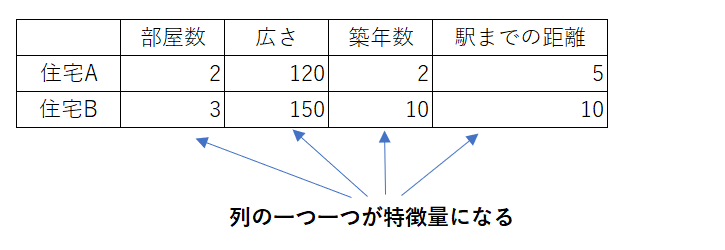
特徴量の例を挙げると、例えばスパムメールを判別するモデルでは、メールに含まれる単語や送信者、メールサイズなどが特徴量となります。または住宅価格の予測では、部屋の数や広さ、築年数、駅までの距離、地域の犯罪率などが特徴量です。
上記からわかるように、データを説明するものが特徴量と言えます。
特徴量は数値(特徴抽出)
ご存じのようにコンピューターはあくまでも計算機であるため、学習で扱えるものは数値のみです。そのため特徴量は数値で表す必要があります。
機械学習を用いた製品に、人間の言葉を理解するものや画像を判別するものがあります。音声や画像のような数値化されていないデータをそのまま用いることはできないため、製品内部ではコンピューターが扱える数値に変換して動いています。
このようなデータを特徴量に変換する作業を特徴抽出と呼びます。
特徴量の質
機械学習で最終的に求められるのは精度の高い予測・分類です。精度の高いモデルを作成するためには質の良い特徴量が不可欠になります。
特徴量の質は選択する特徴量によっても変わりますし、前処理によるデータ形式の変換にもよります。
機械学習における前処理については以下記事をご参照ください。

【機械学習】データの前処理:データ操作について
特徴量の質が悪いと、その分機械学習による予測・分類の精度が低くなるため、機械学習において「データの前処理」は重要な役割を果たしています。
特徴量の変数:目的変数、説明変数
特徴量はすべて数値化されます。プログラムでこの特徴量を利用すると、「変数」として扱います。
この特異量の「変数」は以下の2種類に分けられます。
- 目的変数
- 説明変数
以下の住宅価格を求める機械学習を例にして解説していきます。

目的変数
求めたいもの(予測・分類したいもの)の過去データを目的変数と呼びます。
例では、求めたい「住宅価格」の過去データである「住宅価格」が目的変数となります。
説明変数
目的変数に影響を与える(原因となっている)ものを説明変数と呼びます。そして説明変数は特徴量とイコールの関係です。
例では、目的変数(住宅価格)に影響を与える「部屋数」、「広さ」、「築年数」、「駅までの距離」が説明変数となります。
特徴量と次元
機械学習では次元という言葉もよく見ます。次元は2次元や3次元といった使い方をします。
次元の数は特徴量の数と同じです。特徴量を増やせば次元も増え、減らせば次元も減るという関係です。
例えば住宅の広さ、部屋数、築年数を特徴量にするならば3次元となります。
ここまででわかった特徴量と次元、説明変数の関係は以下のようになります。
特徴量 = 次元の数 = 説明変数の数
特徴量の選択(特徴量選択)
機械学習では精度の高いパターンやルールを導き出せるように、学習の指標となる最適な特徴量を選択する必要があります。
単にたくさんの特徴量を用意すればいいというわけではなく、最適な特徴量を選択することが非常に大切になります。
特徴量選択をすることのメリットとして、次のことが挙げられます。
- 学習時間の削減
- 予測精度の向上
- 過学習を防ぐ
過学習(Overfitting)とは学習したデータだけに過剰に適合してしまい、未知のデータに対する予測精度が低くなることです
特徴量選択には様々な手法が存在します。以下は代表的な特徴量選択の手法です。
フィルタ法
フィルタ法とは各特徴を統計的に点数化し、その点数から特徴量を選び出す手法です。フィルタ法は単変量特徴量選択とも呼ばれます。
特徴量を点数化する手法としては、「カイ二乗検定(Chi-Square)」や「ANOVA(Analytics of Variance)」などが存在します。
組み込み法
組み込み法とは機械学習モデルが学習中に特徴量選択を行う手法です。組み込み法はモデルベース特徴量選択とも呼ばれます。
学習アルゴリズムに特徴量選択が組み込まれていることから、組み込み法と呼ばれています。
簡単に言うと、組み込み法は学習と特徴量選択を同時に行うということです。
組み込み法のアルゴリズムには、「決定木」や「ラッソ回帰」などがあります。
ラッパー法
ラッパー法(Wrapper Method)とは複数の特徴を組み合わせて、最も精度が高い組み合わせを探索する手法です。ラッパー法は反復特徴量選択とも呼ばれます。
様々な特徴量の組み合わせを試すため、特徴量が多いと膨大な計算が必要となります。
まとめ
本記事「【機械学習】特徴量とは?意味や変数、選択について」はいかがでしたか。
機械学習を勉強する上で特徴量は必ず知っておくべき用語です。特徴量について知識を深め、最適な特徴量を選択する必要性を覚えておいてください。
この記事の執筆者


 関連記事
関連記事









